Are you in a special context or did you perform some particular tweaking on your YunoHost instance ?** : no
Not too long ago I removed some backup files manually from my server’s Yunohost/backup folder to gain some drive space. The next time I tried to access the web panel Yunohost Backup functionality it was no longer working (indefinite spinning wheel).
Is there a way I can force a rebuild of the database to recognize what is currently in that folder?
Additionally, one related question
I’ve since cloned my previous hard drive (240gb) to a larger SSD (1TB) using Clonezilla. Everything went well except even though I needed to expand the partition using GParted it now sees the larger drive and the additional storage, unfortunately my Debian server does not. It only sees the original drive size as the size of my home folder.
One common mistake is to delete the anchive bet not the information file that goes with it (same name, different file extension, I think they are .json but I’m not sure at all)
With an inconsistence here, there are problems happening.
Take care when you delete a backup and if possible, do it from the web interhace.
Yes unfortunately that’s exactly what happened. I was running out of space and the regular backup wasn’t responding, so I decided to go this route. Not, ideal:(
Now that I do have the new SSD I was planning on just mirroring the backups from my external drive to counteract what I’ve done. Now if I could only get my OS to recognize the extra space. I’m sure I’m just missing a simple command.
On my side, the backups are all on an external drive.
Do not make the same error as I did first, the «right» way to do this is to make a symlink from /home/yunohost.backup/archives to a folder in your external drive.
At 1st I did the link from yunohost.backup but this causes problems too.
For the backup problems, you can manually remove the files not needed anymore, it will work.
To clarify: there’s no backup database, just files in folders … if yunohost miserably crash then that’s just probably related to yunohost trying to list some .tar.gz or .info.json file that got deleted but not its counterpart (though that remains a bug and should be fixed upstream … but for this we need the logs of the actual error somehow )
Sorry, I was only assumed this was what was going on, I simply removed some of the oldest backups from the Yunohost/backup folder.
I was considering migrating to Buster and Yunohost 4x, maybe this would be a good time to do that.
The good news is that since I’ve cloned my drive if anything horrible happens I can just re-clone it.
Are you familiar with partitions on the one hand and filesystems on the other?
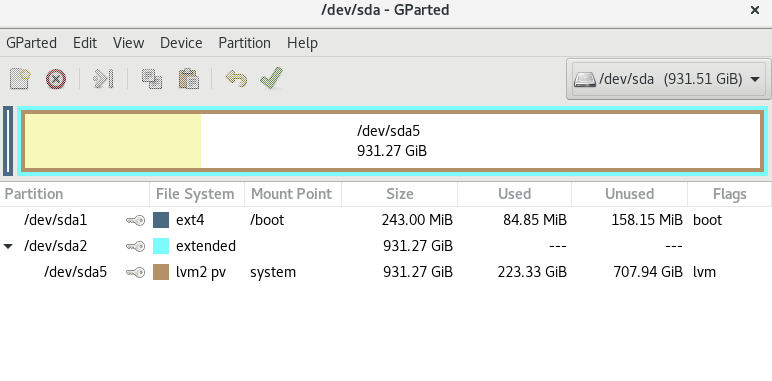
GParted has an option to resizy the filesystem consistently with the partition resizing, but I am not sure whether it is turned on by default.
What I imagine happened, is that the partition (/dev/sda1 for example) got resized, but the filesystem (ext4, most probably) not.
Ok, you got a pile of abstractions from harddisk to files:
physical SSD, eg /dev/sda
partitions, eg /dev/sda5
LVM physical volumes and volume groups (/dev/sda5 and any name you used for volume group)
LVM logical volumes, /dev/mapper/system (or any name)
filesystems, such as ext4 and btrfs, that you can mount on / or /home
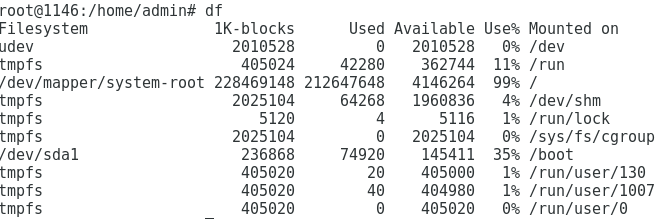
If you type df (disk free, I guess), you get a list of partitions, size, free space and mount points.
It will probably show /dev/mapper/‘any name’ with some 240G of space, mostly used.
If you type pvs (physical volume scan), vgs (volume group scan) or lvs (logical volume scan) you get information on the size of those LVM ingredients. pvs will show a physical volume of 930G, with 700+G free.
You’ll have to resize the logical volume, and if the filesystem is ext4, let it resize that in one go.
First dry run:
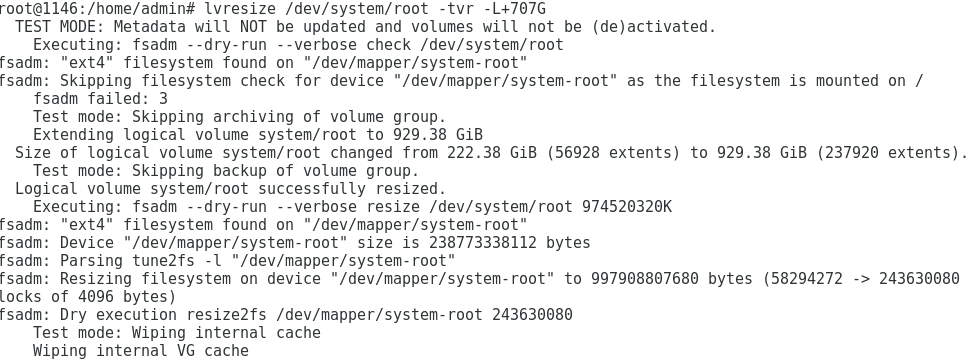
lvresize system -tvr -L+700G
then, on no errors, execute:
lvresize system -vr -L+700G
Notice the ‘t’ for test.
‘system’ is the name of the volume you want to resize, the ‘r’ option is to resize the filesystem.
I managed to find the right path, I think, to run the test command although I’m not sure if the “fsadm failed: 3” is simply because the drive is mounted.
Checking the filesystem doesn’t work when it is mounted, I think you are right that ‘fsadm failed: 3’ is because of that.
I recall I usually resize online, that is, without unmounting. You got a backup because you just mirrored your disk, haven’t you?
If so, run the command with -vr (without the t for test).
%< - - %< - - %< - -
Another option is to create a new volume that will hold the growing data.
In that case: see which directory(tree) takes most of your current 220G. Imagine it is under /var ; then make a new logical volume (lvcreate) and filesystem (mkfs.ext4) and copy everything from /var to that new filesystem. Then change /etc/fstab to mount the new volume at /var ; rename the current /var to /var_old and mount the new one. Finally delete /var_old to reclaim used space.
Those are quite a few steps that may or may not sound complicated. We can look at it in more detail if the easy way does not work out
If the easy way does not work, I would guess it will cancel the actions at the step where it wants to check the filesystem. I can’t remember ever losing data during an action like this (that can be me being lucky or just problems with selective memory). I have always been very happy with LVM and the flexibility it provides.
Worst case would indeed be needing to reclone your disk from backup. How many people are using your server, and how much new data would you lose?
I just read your introduction: your have ‘easy’ access to your system and disks, so if you can afford the downtime, you can use another (live) distro to perform the action. Maybe you can use your old installation for that, but maybe some part of LVM will get confused because the names on the old disk are identical. You could even create a new logical volume in /dev/sda5 and install a rescue distro. You can keep the size just big enough for the distro you choose.
So, to recapitulate the options:
Perform live resizing of /dev/mapper/system-root with the command as you test-ran;
You might perform a fsck.ext4 on next boot (of course before the resizing; by putting an empty file ‘forcefsck’ in / with ‘sudo touch /forcefsck’ ). That way any errors that fsck would have found during the resize, will be already dealt with.
+ easiest and fastest option
- I don’t know what happens because it is the root filesystem
Create a new lvm logical volume and partition, migrate data and let it grow on the new partition;
+ no specific risk
- most complex option
Boot another distribution to perform the resizing. Then /dev/mapper/system-root of your 1TB will not be mounted, and the filesystem check can be performed.
Depending on the (live) distro, you might need to install lvm2.
+ Lowest risk
- Needs another distro
If my backup was recent enough, I would take option 1 myself.