Bonjour à tous.
J’ai un petit cailloux dans ma chaussure et je ne trouve pas de solution… Peut-être que mes compétences s’arrêtent où commencent les votres (J’espère en fait…)
Mon serveur YunoHost
Matériel: Cloud VPS chez onetsolution, 2Go de RAM, 120Go SSD, 2coeurs
{
"host": "Debian 9.12",
"kernel": "4.9.0-12-amd64",
"packages": {
"yunohost": {
"repo": "stable",
"version": "3.6.5.3"
},
"yunohost-admin": {
"repo": "stable",
"version": "3.6.5.1"
},
"moulinette": {
"repo": "stable",
"version": "3.6.4.1"
},
"ssowat": {
"repo": "stable",
"version": "3.6.4"
}
},
"backports": [],
"system": {
"disks": {
"dm-0": "Mounted on /, 95.7GiB (71.5GiB free)",
"sda1": "Mounted on /boot, 235.3MiB (173.0MiB free)"
},
"memory": {
"ram": "1.9GiB (1.2GiB free)",
"swap": "2.0GiB (2.0GiB free)"
}
},
"nginx": [
"nginx: the configuration file /etc/nginx/nginx.conf syntax is ok",
"nginx: configuration file /etc/nginx/nginx.conf test is successful"
],
"services": {
"glances": "running (enabled)",
"nslcd": "running (enabled)",
"postgresql": "exited (enabled)",
"metronome": "running (enabled)",
"postfix": "exited (enabled)",
"rspamd": "running (enabled)",
"yunohost-firewall": "exited (enabled)",
"nginx": "running (enabled)",
"php7.0-fpm": "running (enabled)",
"dnsmasq": "running (enabled)",
"fail2ban": "running (enabled)",
"yunohost-api": "running (enabled)",
"mysql": "running (enabled)",
"avahi-daemon": "running (enabled)",
"dovecot": "running (enabled)",
"redis-server": "running (enabled)",
"slapd": "running (enabled)",
"ssh": "running (enabled)"
},
"applications": {
"onlyoffice": "OnlyOffice",
"ampache": "Ampache",
"nextcloud": "Nextcloud"
},
"security": {
"CVE-2017-5754": {
"name": "meltdown",
"vulnerable": false
}
}
}
J’ai accès à mon serveur : En SSH | Par la webadmin
Êtes-vous dans un contexte particulier ou avez-vous effectué des modificiations particulières sur votre instance ? : une seule :
La modif : pm.max_children = 8 dans le nextcloud.conf (au lieu de 4 par défaut)
Description du problème
J’ai installé sans difficulté Yunohost dont je me sert pour me dégoogliser depuis plusieurs mois. J’utilise nextcloud et ampache principalement. Aucune panne à signaler.
Depuis mi Janvier environ, le serveur virtuel s’arrête tous les 2 à 3 jours… sans prévenir.
Je relance la machine, tout repart nickel… puis arrêt à nouveau deux jours plus tards.
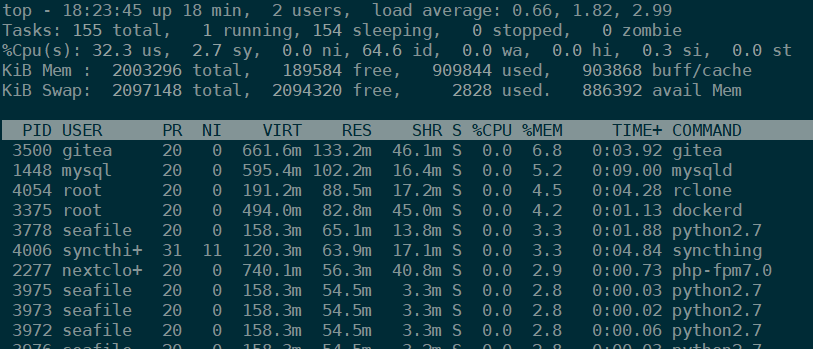
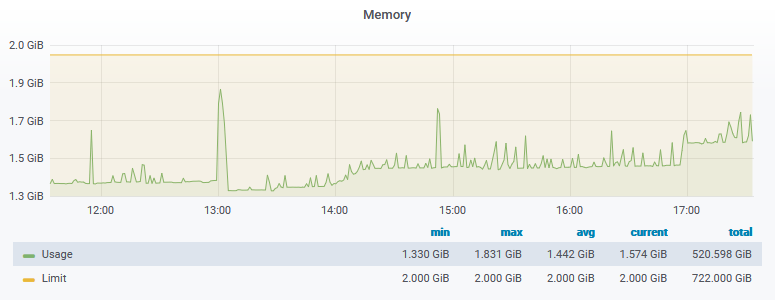
Je constate avec l’outil de monitoring de l’hébergeur que l’utilisation de la mémoire augmente constament puis se stabilise juste sous la limite du serveur (2Go). Pourquoi la mémoire augmente en permanence même sans utilisation (un cron à la con qui serait buggé?)? Est-ce que le problème vient de là : lorsque le serveur atteint la limite, il tue les process au hasard?
J’ai posé la question à l’hébergeur qui ne retrouve aucun trace de problème ou de stabilité de ses machines.
Voici ce que je constate :
Syslog :
Mar 20 20:09:01 rby CRON[22805]: (root) CMD ( [ -x /usr/lib/php/sessionclean ] && if [ ! -d /run/systemd/system ]; then /usr/lib/php/sessionclean; fi)
Mar 20 20:09:05 rby systemd[1]: Starting Clean php session files...
Mar 20 20:09:05 rby systemd[1]: Started Clean php session files.
Mar 21 08:42:17 rby systemd[1]: Starting Flush Journal to Persistent Storage...
Mar 21 08:42:18 rby fake-hwclock[470]: Current system time: 2020-03-21 07:42:09
Mar 21 08:42:18 rby fake-hwclock[470]: fake-hwclock saved clock information is in the past: 2020-03-20 18:17:02
Mar 21 08:42:18 rby fake-hwclock[470]: To set system time to this saved clock anyway, use "force"
Mar 21 08:42:18 rby systemd[1]: Started Flush Journal to Persistent Storage.
J’ai ça aussi mais on dirait que c’est une tâche automatique :
Mar 19 06:25:01 rby CRON[13161]: (root) CMD (test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ))
Mar 19 06:25:01 rby CRON[13164]: (root) CMD (command -v debian-sa1 > /dev/null && debian-sa1 1 1)
Mar 19 06:25:05 rby slapd[1264]: slap_global_control: unrecognized control: 1.3.6.1.4.1.4203.666.5.16
Mar 19 06:25:08 rby systemd[1]: Stopping Supervisor process control system for UNIX...
Mar 19 06:25:11 rby supervisorctl[13357]: Shut down
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,596 INFO waiting for metrics, spellchecker, gc, docservice, converter to die
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,620 WARN received SIGTERM indicating exit request
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,707 INFO stopped: metrics (exit status 0)
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,722 INFO stopped: converter (terminated by SIGTERM)
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,797 INFO stopped: spellchecker (terminated by SIGTERM)
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,818 INFO stopped: docservice (terminated by SIGTERM)
Mar 19 06:25:11 rby supervisord[938]: 2020-03-19 06:25:11,911 INFO stopped: gc (terminated by SIGTERM)
Mar 19 06:25:12 rby systemd[1]: Stopped Supervisor process control system for UNIX.
Mar 19 06:25:12 rby systemd[1]: Started Supervisor process control system for UNIX.
Mar 19 06:25:12 rby systemd[1]: Reloading LSB: Metronome XMPP Server.
Mar 19 06:25:13 rby metronome[13375]: Reloading Metronome XMPP Server: metronome.
Mar 19 06:25:13 rby systemd[1]: Reloaded LSB: Metronome XMPP Server.
Hier soir il s’est arreté mais il a redémarré seul… A ne rien comprendre
Journal de php
[19-Mar-2020 19:01:45] NOTICE: [pool nextcloud] child 26261 exited with code 0 after 10371.711904 seconds from start
[19-Mar-2020 19:01:45] NOTICE: [pool nextcloud] child 31197 started
[19-Mar-2020 20:21:17] NOTICE: [pool nextcloud] child 27860 exited with code 0 after 10952.023409 seconds from start
[19-Mar-2020 20:21:17] NOTICE: [pool nextcloud] child 616 started
[21-Mar-2020 08:42:42] NOTICE: fpm is running, pid 935
[21-Mar-2020 08:42:43] NOTICE: ready to handle connections
[21-Mar-2020 08:42:43] NOTICE: systemd monitor interval set to 10000ms
[21-Mar-2020 11:12:55] WARNING: [pool nextcloud] seems busy (you may need to increase pm.start_servers, or pm.min/max_spare_servers), spawning 8 children, there are 0 idle, and 7 total children
[21-Mar-2020 11:12:56] WARNING: [pool nextcloud] server reached pm.max_children setting (8), consider raising it