Ici il y a tout de même un regen-conf à appliquer
et ici aussi
Tu devrais déjà exécuter cela
yunohost tools regen-conf --force
Ici il y a tout de même un regen-conf à appliquer
et ici aussi
Tu devrais déjà exécuter cela
yunohost tools regen-conf --force
Je regarde les applications installées.
J’essaye de chercher dans les dépôts github des app pour voir si je trouve quelque chose qui indique que nchan est une dépendance de l’un ou l’autre mais je ne trouve pas.
Où est-ce que je peux voir les dépendances installée avec une application ?
Oui, j’ai bien ce paquet d’ailleurs… et j’ai bien aussi le paquet libnginx-mod-nchan installé, il doit aussi être là d’origine… Désolé pour la confusion
Pas de problème, merci pour le temps passé à essayer de m’aider. ![]()
J’ai pu restaurer nextcloud mais j’arrive sur :
Internal Server Error
The server encountered an internal error and was unable to complete your request.
Please contact the server administrator if this error reappears multiple times, please include the technical details below in your report.
More details can be found in the server log.
C’est pas encore terminé…
J’ai régénéré la configuration comme tu l’as proposé :
# yunohost tools regen-conf --force
Success! Configuration updated for 'yunohost'
Success! Configuration updated for 'apt'
Success! Configuration updated for 'dnsmasq'
apt:
applied:
/etc/apt/sources.list.d/extra_php_version.list:
status: force-updated
pending:
dnsmasq:
applied:
/etc/resolv.dnsmasq.conf:
status: updated
pending:
yunohost:
applied:
/etc/systemd/system/ntp.service.d/ynh-override.conf:
status: force-removed
pending:
Je viens de me rendre compte que Gitea était également désinstallé.
# yunohost backup restore gitea-pre-upgrade1
(...)
Success! Restoration completed
Je confirme que j’ai à nouveau accès à Gitea.
Et actuellement, Nextcloud est toujours planté (internal server error).
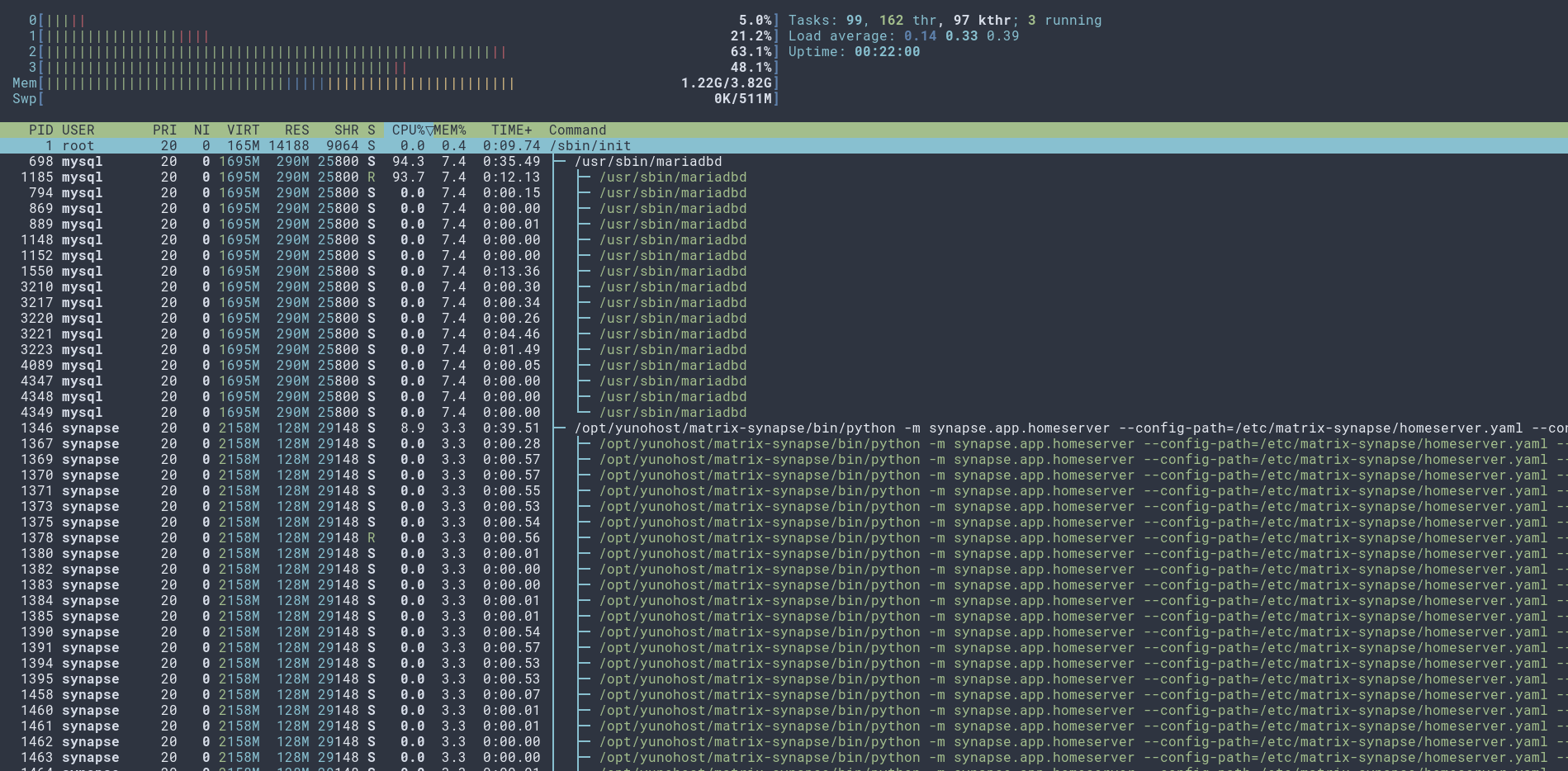
Un sudo htop ou sudo btop pourrait éclairer un peu. Peut être un reboot
J’ai fait un reboot, ça n’a rien changé pour nextcloud.
$ sudo htop
sudo btop
Je ne vois rien d’anormal jusqu’ici. Le serveur est à la cool, pas trop de mémoire utilisée, pas trop de trafic réseau, …
Pour mettre le serveur complètement à jour, je dois appliquer une mise à jour pour Element, pour Synapse et pour Nextcloud.
La dernière fois je l’avais fait via la webadmin mais peut-être que c’est ça qui a causé le problème ? Ici j’ai décidé de le faire en ligne de commande, dans tmux pour être sûr.
# yunohost app upgrade element
Info: Now upgrading element…
(...)
Success! Upgrade complete
Element fonctionne. On passe à la suite.
# yunohost app upgrade synapse
Info: Now upgrading synapse…
(...)
Success! synapse upgraded
Ça semble OK pour Synapse également.
Je lance l’upgrade pour nextcloud.
# yunohost app upgrade nextcloud
(...)
Success! nextcloud upgraded
Yes, Nextcloud fonctionne à nouveau ! ![]()
Résumons…
Nginx a commencé à mettre plus de temps à démarrer (pourquoi? C’est encore un mystère…). À cause de ça, plusieurs mises à jours d’application se sont mal passés (Gitea sans que je m’en rende compte, Element et puis Nextcloud).
La solution a été d’augmenter le temps avant un timeout.
[Service]
Type=forking
PIDFile=/run/nginx.pid
(...)
TimeoutStartSec=300
Grâce à ça, j’ai pu restaurer Gitea et ensuite mettre à jour Element, Synapse et puis Nextcloud (qui était planté..). J’ai à nouveau un serveur fonctionnel.
Cependant je n’ai toujours pas compris ce qui rend le démarrage de Nginx si lent. Ça me semble anormal de devoir mettre un délais avant timeout de 5 minutes.
J’ai donc du mal à considérer le problème comme résolu.
Je vois deux pistes :
Voyez-vous une autre possibilité ?
En fait, je pensais ouvrir trois ou quatre terminaux. Un avec sudo btop, un autre avec sudo journalctl -f, un autre avec sudo iotop et un dernier pour lancer sudo systemctl restart nginx .
Y’aura bien un qui va dire ce qui se passe
Bonsoir,
Si ce n’est déjà fait, peut-être peux-tu mettre temporairement* error_log /var/log/nginx/error.log debug ; pour des logs un peu plus verbeux et recréer la condition du plantage en ramenant le timeout à 90 ?
(*c’est effroyablement verbeux)
Je n’ai plus eu le temps hier et la semaine a recommencé… J’essaye de tester vos propositions au plus vite.
Je suis pris par le quotidien, je trouve pas le temps de tester les choses… ![]()
The issue is definitely about
Apr 11 18:40:01 artanux.be systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server...
Apr 11 18:41:31 artanux.be systemd[1]: nginx.service: start-pre operation timed out. Terminating.
Apr 11 18:41:31 artanux.be systemd[1]: nginx.service: Control process exited, code=killed, status=15/TERM
which i saw a few times in the past (for example here) but unfortunately is pretty fuzzy and it’s not clear to me what could be causing this in the first place (nor apparently how you managed to solve it apparently?)
The “Start-Pre” operation is apparently, according to systemctl cat nginx :
ExecStartPre=/usr/sbin/nginx -t -q -g 'daemon on; master_process on;'
which is basically just nginx -t … plus the -g option which is a bit obscure to me
Searching on Google, this article is talking about OCSP stapling but that doesn’t seem to correspond to YunoHost’s context
This thread is talking about PID=/run/nginx.pid versus PID=/run/nginx/nginx.pid (in the systemd conf) but I doubt this is the issue (why would your conf be different than anybody else and why was it working in the past..)
Soooo idk, maybe if the issue pops back up, I would try manually running the “StartPre” operation (/usr/sbin/nginx -t -q -g 'daemon on; master_process on;) to see if that command is indeed taking an unusual amount of time (more than a (few?) second)
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.